Bellman Equations
Reinforcement Learning covers whole new concept compared to traditional supervised learning. Therefore, the idea of RL is difficult to grasp in a first sense. While studying RL, I realized obtaining concrete understanding of basic building blocks that consists RL is a highly crucial task. This post covers second crucial stepping stone in understanding reinforcement learning, Bellman Equation. Again, the post was written in reference to awesome introductory video about reinforcement learning made by the Youtube channel Mutual Information. Detailed information is written below footnote.1
Table of contents
Dynamic Programming
What is Dynamic Programming?
Dynamic Programming (DP) is a method used in mathematics and computer science to solve complex problems by breaking them down into simpler subproblems. By solving each subproblem only once and storing the results, it avoids redundant computations, leading to more efficient solutions for a wide range of problems.2 Key notions involved in dynamic programming are optimal decesion making and solving subproblems.
Condtions to Become a DP Problem
 What makes DP Problems3
What makes DP Problems3
-
Optimal Substructures In computer science, a problem is siad to have optimal substructure if an optimal solution can be constructed from optimal solutions of its subproblems.4
-
Overlapping Subproblems In computer science, a problem is said to have overlapping subproblems if the problem can be broken down into subproblems which are reused several times or a recursive algorithm for the problem sovles the same subproblem over and over rather than always generating new subproblems. For exmaple, computing the Fibonacci Sequence exhibits overlapping subproblems.5
Bellman Equations
Bellman Equation for \(\mathcal{v}_{\pi}(s)\)
Let’s focus on state \(s_0\). From this state, the agent can pick action \(a_0\). According to agent’s action \(a_0\), the reward and next state probability will be given by some distribution. For example, like the chart as below:
| Reward | State \(s_1\) | State \(s_2\) |
|---|---|---|
| 0 | 0.12 | 0.09 |
| 1 | 0.5 | 0.23 |
| 2 | 0.4 | 0.01 |
For example, (1,3) cell tells us under some action \(a_0\), there is a 9% chance that the agent will end up in \(s_2\) with the reward of 0. Underlying logics are true for the different possible actions. Then, how actions are determined? The policy handles this.
For example, we can say, if there is two possible actions of going left or rihgt, an arbitrary action \(a_0\) are determined by the policy such that:
\[\pi(\leftarrow | s_0) = 0.4 \quad \text{40% of choosing action right}\] \[\pi(\rightarrow | s_0) = 0.6 \quad \text{60% of choosing action left}\]with a discount factor \(\gamma = 0.9\).
Given this information, let’s recall what we’re going to calculate. If we restate the value function in terms of state \(s_0\):
\[\begin{aligned} v_{\pi}(s_0) &= \mathbb{E}_{\pi}\left[G_t|s_0\right] \\ &= \sum_{a \in \leftarrow, \rightarrow} \pi(a|s_0)\mathbb{E}_{\pi}\left[G_t|s_0,a\right] \end{aligned}\]We break this down by action, meaning sum of two terms, one for the left action and one for the right action. Each term will be the expected return conditional on the current state and the action \(E_{\pi}[G_t|s_0,a] \Leftrightarrow q_{\pi}(s_0, a)\): action value, weighted by the probability of taking each action.
Note that \(G_t\) obeys recursion: \(G_t = R_{t+1} + \gamma G_{t+1}\). \(G_t\) is equal to the current reward plus total future reward of next step.
\[\begin{aligned} G_t & = R_{t+1} + \gamma R_{t+2} + \gamma^{2}R_{t+3} + \dots \newline & = R_{t+1} + \gamma(R_{t+2} + \gamma R_{t+3} + \dots) \newline & (\text{where} (R_{t+2} + \gamma R_{t+3} + \dots) = G_{t+1}) \end{aligned}\]Let’s rewrite expected return under policy \(\pi\) and given state \(s_0\) and action \(\rightarrow\). Considering total future reward \(G_t\) and its relationship with action-value function, we say:
\[\begin{aligned} \mathbb{E}_{\pi}[G_t|s_0, \rightarrow] & =\mathbb{E}_{\pi}[R_{t+1} + \gamma G_{t+1} | s_0, \rightarrow] \\ & =\mathbb{E}_{\pi}[R_{t+1} + \gamma \mathcal{v}_{\pi}(S_{t+1} | s_0), \rightarrow] \end{aligned}\]From the uppper equation, \(R_{t+1} \text{ and } S_{t+1}\) are just random variables, probability weighted average of values that we can find somewhere like distribution tables that we talked earlier. Specifically, this will equal a sum over all pairs of reward and next state, in our example, \(r \in {0,1,2}, \ s \in {s_1, s_2}\).
\[\mathbb{E}_{\pi}[G_t|s_0, \rightarrow] = \sum_{r \in {0,1,2} \atop s \in {s_1, s_2}} p(s', r|s, \rightarrow)[r + \gamma \mathcal{v}_{\pi}(s')]\]Each term will be weighted by its probability \(p(s’, r|s, \rightarrow)\), and each term itself is \([r + \gamma v_{\pi}(s’)]\). Lastly, we have \(\mathcal{v}_{\pi}(s’)\) in our hand to calculate the whole term. However, things are not done yet, since we should calculate the same for the whoel aciton set, in our case, \(\leftarrow\) action.
In a nutshell, bellman equation connects all state values. If we can solve some state values, that means we can solve all state values.
Bellman Optimality
But, stories aren’t finished yet. So far, we’ve connected all state values of some policy. However, our final goal is to the optimal policy!
- Optimal state-value function gives the highest possible values across all policies.
- Optimal action-value function gives the highest possible values across all policies per state-action pairs.
For example, what is optimal state-value \(\mathcal{v}^*(s^0)\) under such action-value function values?
\[q^*(s^0, \leftarrow) = 19.1 \quad q^*(s^0, \rightarrow) = 21.3\]Without a doubt, optimal state-value would be the action-value function with bigger value, action-value function conditioned to \(\rightarrow\) action. Therefore, by conditioning optimal state-value function to pick an action that maximizes the value of action-value function, we can find optimal policy.
\[\mathcal{v}^*(s^0) = \max_{a \in \{\leftarrow, \rightarrow \}} q^*(s^0, a)\]The agent must always select the highest action value, otherwise the agent is not behaving optimally. In other words, the state value must be the maximum over optimal action values.
Policy Evaluation
Objective: Compute \(v_{\pi}(s)\) or \(q_{\pi}(s,a)\) for a given \(\pi\).
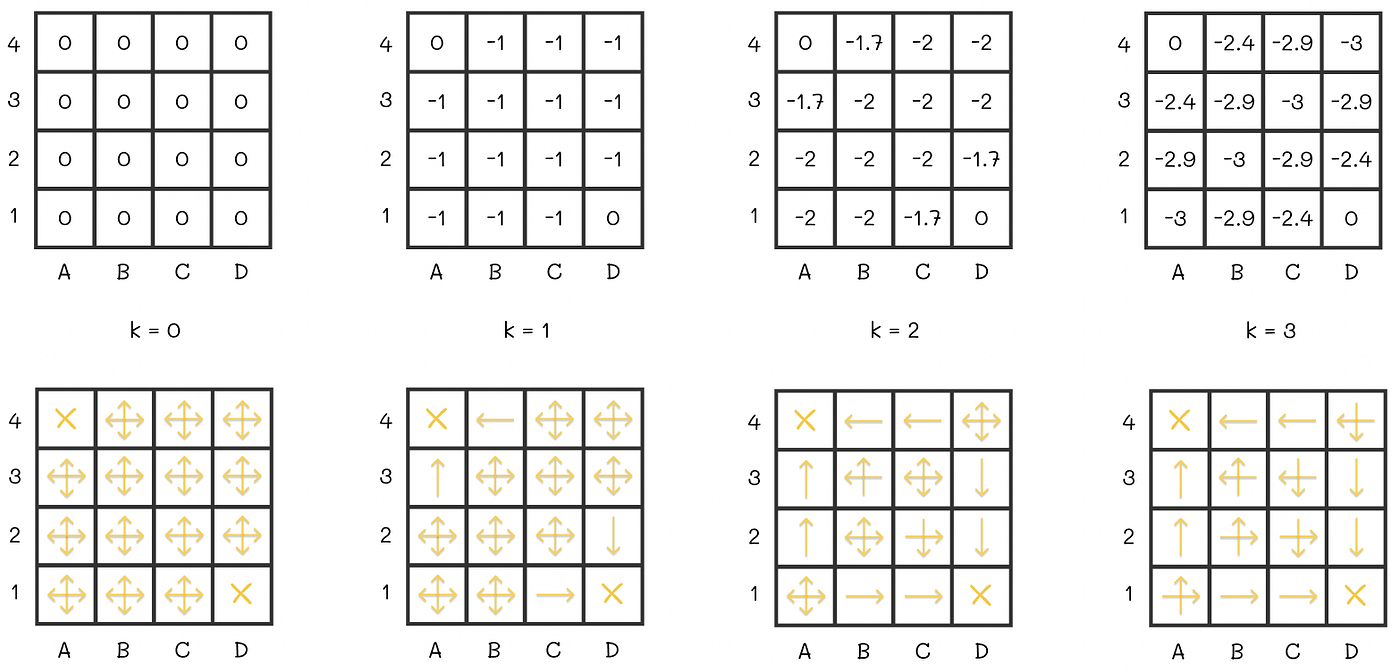 Random initialization, update cell values w.r.t actions, repeat and converge6
Random initialization, update cell values w.r.t actions, repeat and converge6
- Turn Bellman equation into an assignment and repeatedely apply starting from random values.
- Doing step 1. forms a sweep, which means one path over all states
- Repeat sweeps until the values stop changing by more than some small amount
- And this process always converges to the right answer.
Policy Improvement
Objective: Compute \(\mathcal{v}_{\pi}(s)\), determine a better policy than \(\pi\)
Below content from 15:52, Bellman Equations, Dynamic Programming, Generalized Policy Iteration Reinforcement Learning Part 2, Mutual Information
Given \(\mathcal{v}_{\pi}(s)\), determine a better policy than \(\pi\).
Say \(\pi\) is deterministic: \(a=\pi(s)\)
For an optimal policy \({\pi}^*\): \({\pi}^*(s) = \arg \max_{a} q^*(s,a)\)
Define a new policy \(\pi’\): \({\pi}'(s) = \arg \max_{a} q_{\pi}(s,a)\)
Due to the Policy Improvement Theorem: \(v_{\pi}(s) \leq v_{\pi'}(s) \quad \forall \ s \in S\)
If \(\pi\) is greedy w.r.t \(v_{\pi}\), then \(\pi = \pi^*\).
Greedy Algorithm: In computer science, a greedy algorithm is an algorithm that finds a solution to problems in the shortest time possible. It picks the path that seems optimal at the moment without regard for the overall optimization of the solution that would be formed.7
-
Referenced this video, Mutual Information, Reinforcement Learning, by the Book ↩
-
Definition of Dynamic Programming ,Geeks For Geeks ↩
-
Image from this page, FavTutor, Shivali Bhadaniya, Dynamic Programming in Python: Top 10 Problems (with code) ↩
-
Image from this page, Medium, Vyacheslav Efimov, Reinforcement Learning, Part 2: Policy Evaluation and Improvement ↩
-
*Definition of Greedy Algorithm, Free Code Camp, Tantoluwa Heritage Alabi, What is a Greedy Algorithm? Examples of Greedy Algorithms ↩