Seq2seq
This post covers Seq2Seq Encoder-Decoder Architecture. Seq2Seq architecture is heavily used in areas such as Machine Translation, Natural Language Processing, Chat Bots, etc. This post heavily referenced Josh Starmer’s Sequence-to-Sequence (seq2seq) Encoder-Decoder Neural Networks, Clearly Explained!!! video.
Table of contents
Related Issues
- Issue of different length: In machine translation process, there is a problem of unmatching number of input vectors and desired output vectors.
- In other words, in most of the cases, sequences of one type of thing would not be in 1-to-1 relationship with sequences of another type of thing.
Intuition
 Encoder-Decoder Architecture Figure1
Encoder-Decoder Architecture Figure1
- I first learn the representation of the English sentence.
- The entire representation is in the output of the blue RNN cells.
- Then pass that representation vector into decoder architecture - white cells.
- Decoder parts starts with encoder’s input and the EOS signal.
As you can recognize, that one output vector of encoder architecture is doing a lot of heavy lifting. That one vector is trying to represent the entirely of the English sentence. Currently, it’s not a long sentence, but imagine that sentence length grows. This could be a challenging problem.
Building Encoders
Materials we need
- One-hot vectors of words
- Word2Vec embedding layers (~ 200K tokens with 1K embedding dimensions)
- LSTM units (~ 4 layers with 1K LSTM cells per layer)
- LSTM units can be doubled or stacked.
- Doubled LSTM cells have their own, separate sets of weights and biases.
- Stacked LSTM cells are additional layers. The output values from the unrolled LSTM units in the first layer(the short-term memories, or hidden states) are used as the inputs to the unrolled LSTM units in the second layer.
Architecture of Encoders
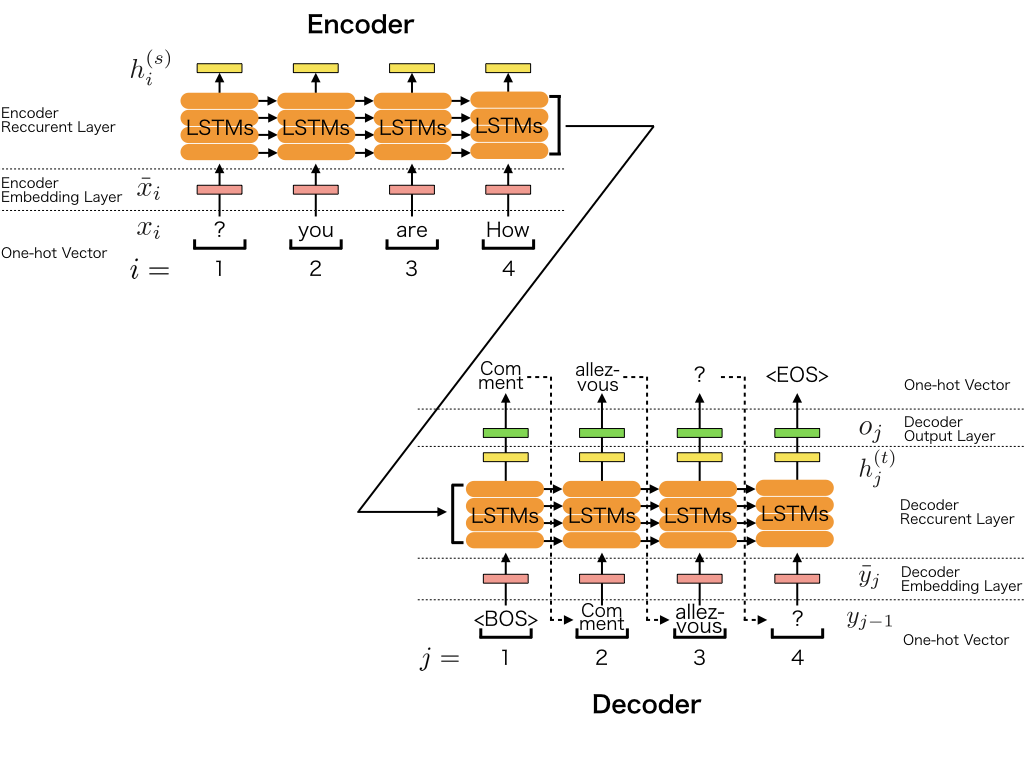 Encoder-Decoder Architecture Detailed Figure2
Encoder-Decoder Architecture Detailed Figure2
In essence, the Encoder encodes the input sentence into a collection of long and short term memories, which is called Context Vector.
Building Decoders
Decodrs are named decoders because they decodes input context vector. Then, how do they manage this task?
Materials we need
- New set of LSTMs - these LSTMs have their own and separate weights and biases, different from the ones in the Encoder.
- Embedding layers that provide the input to the LSTM cells in the first layer. However, embedding layers here contains target language sets. (~ 80K tokens)
- Fully connected layer - additionally transforms weights and biases values from the LSTM layers.
- Number of inputs: matches input from LSTM layers. (~ 1K inputs <=> 1K LSTM cells in the 4th layer)
- Number of outputs: matches input from embedding layers. (~ 80K outputs <=> size of the output vocabulary)
- Additionally adjusted weights and biases in between inputs and outputs.
- Softmax function
- Input: Output from FC layer.
- Output: Target word representation.
When to stop?
We unroll LSTM until the next predicted token from Softmax function is
Working order of Decoders
- Context vectors are used to initialize the LSTMs in the Decoder.
- Another input to the decoder’s LSTMs comes from the word embedding layer that starts with
. - But subsequently uses whatever word was predicted by the previously unrolled LSTM layer
- Decoders keep predicts words until it predicts the
token, or hits some maximum output length.
Training Encoder-Decoder
Teacher Forcing
- While training, instead of using predicted token for subsequently unrolled LSTMs, we use the known and correct token, no matter of the model’s current prediction.
- Also the model stops predicting even if it doesn’t hit
by its predction, rather it stops where **the known phase ends**.
-
Figure from this article ↩
-
Figure from this article ↩