Word Embeddings Clone Coding
This post is a word embedding clone coding workshop following Coding Lane’s tutorial video. Original content can be found this GitHub repository.
Table of contents
Code Flow
This is the basic outline of how model is trained to embed words.
- Remove stop words and tokenize
- Stop words are words like ‘the’, ‘is’, ‘are’, ‘can’, etc. That don’t lie on the correlationship among different words.
- For efficiencty, these stop words are cleaned in this tutorial example.
- Creating Bigrams
- Bigrams are all possible sets of two different words that appear in a given sentence.
- One-hot encoding
- One-hot encoding is a vanilla approach of representing different words.
- We need one-hot encoded vectors to represent all words for input and output of neural network.
- Build neural network
- Usually, word embedding is not a super complex deep neural network.
- It is consisted of three layers - an input, one hidden, and an output layer.
- For the output layer, we use Softmax activation function.
- Throw data into the NN
- X and Y are onehot representation of bigram word set resprectively.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input
model = Sequential()
vocal_size = len(onehot_data[0])
embed_size = 2
model.add(Input(shape = (vocal_size,)))
model.add(Dense(embed_size, activation = 'linear'))
model.add(Dense(vocal_size, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer = 'adam')
X = []
Y = []
for bi in bigrams:
X.append(onehot_dict[bi[0]])
Y.append(onehot_dict[bi[1]])
X = np.array(X)
Y = np.array(Y)
model.fit(X, Y, epochs = 1000)
Why Biagrams?
Here, we use biagrams to learn the relationships between pairs of words (bigrams) based on the provided data. The provided data 𝑋 and 𝑌 work as usual input and output of supervised learning, where 𝑋 represents input and 𝑌 represents label, the ground truth. Based on this information, the model will predict the value, then compare the prediction with label, finally tries to minimize the error.
NN Architecture
 Neural network acthiecture diagram1
Neural network acthiecture diagram1
Input Layer
Why does input layer has twelve nodes? This is because we are training using total 12 words in this example. Each node can be either 0 or 1, by combining 12 nodes the whole input layer represent a word in an one-hot vector form.
Hidden Layer
This neural network is a fully connected model. Every 12 nodes are connected to two hidden layer nodes. The number of hidden layer is abitrary. In this example, number 2 was chosen to show the relationship among words in 2-dimensional. The number of hidden layer represents the number of features as well as the number of dimensions we want to use.
Output Layer
In word embedding models, the number of output nodes are same as the number of input nodes. This is because the output should be a word in an one-hot vector format. Through numerous iteration, the neural network will adjust weights from hidden layer to output layer and use these weights to produce predicted value. Since word embedding is multiple classification problem, Softmax activation function is used.
Training Result
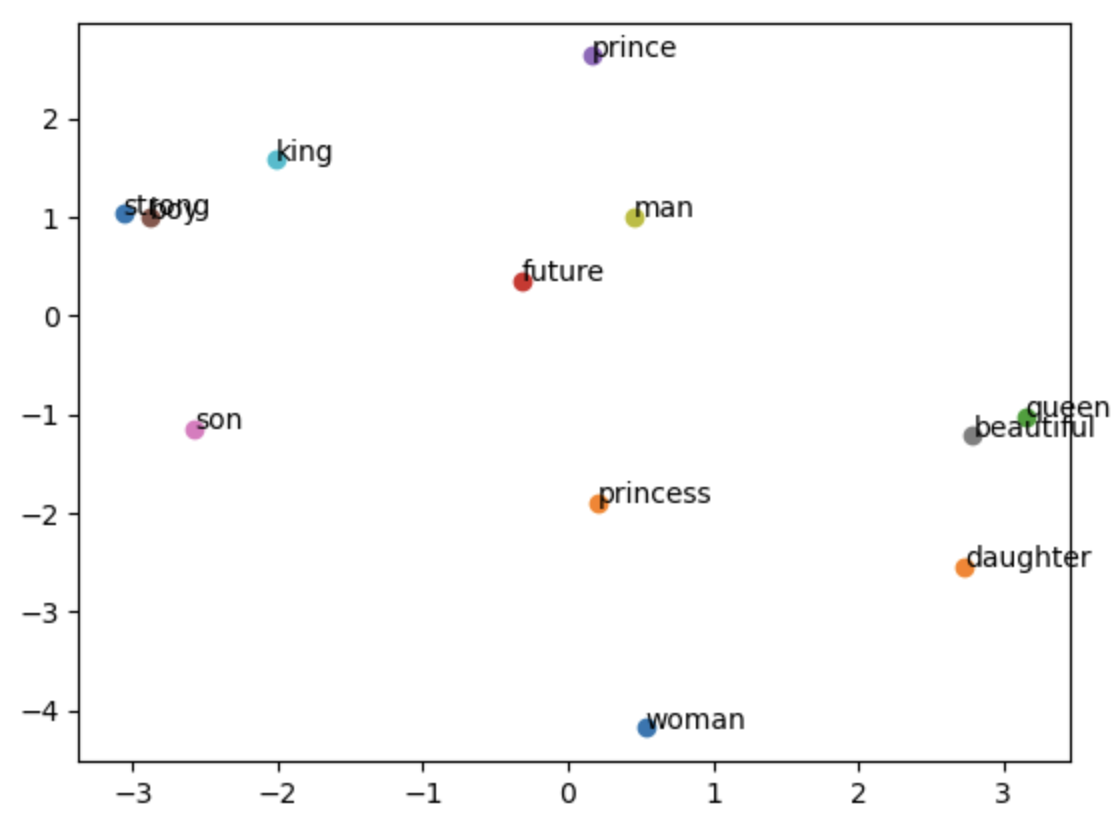
weights = model.get_weights()[0]
word_embedding = {}
for word in all_words:
word_embedding[word] = weights[words_dict[word]]
for word in all_words:
print(word, ":", word_embedding[word])
"""
strong : [-3.063068 1.0315365]
princess : [ 0.20351304 -1.8951936 ]
queen : [ 3.1519506 -1.0218129]
future : [-0.31961027 0.35243037]
prince : [0.16318358 2.6298137 ]
boy : [-2.8832362 0.98850095]
son : [-2.573118 -1.1412688]
beautiful : [ 2.7894583 -1.2159088]
man : [0.45705894 1.0049443 ]
king : [-2.0138352 1.5787313]
woman : [ 0.5316905 -4.1797066]
daughter : [ 2.7295702 -2.5480626]
"""
Each word has two weights. These weights can be written on the line between two hidden nodes and tweleve output nodes. Recall that each word has only one activated node, which has two connected lines to the hidden layer. You can imagine that there is a weight value per line.